【视频】支持向量机算法原理和Python用户流失数据挖掘SVM实例(下)
2024-04-29 284 发布于山西
版权
举报
版权声明:
本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《 阿里云开发者社区用户服务协议》和 《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写 侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
简介: 【视频】支持向量机算法原理和Python用户流失数据挖掘SVM实例(下)
【视频】支持向量机算法原理和Python用户流失数据挖掘SVM实例(上):https://developer.aliyun.com/article/1496748
刚上新酒店 60 #未登录APP 118avgprice 0 填充一部分价格填充为0 近一年未下过订单的人数,cr 用0填充,
tkq = ["hstoryvsit_7ordernm","historyviit_visit_detaipagenum","frstorder_b","historyvi # tbkq = ["hitoryvsit_7dernum","hisryvisit_isit_detailagenum"] X_train[i].fillna(0,inplace=True)
## 一部分用0填充,一部分用中位數填充 # 新用戶影響的相關屬性:ic_sniti,cosuing_cacity n_l = picesensitive","onsmng_cpacty"] fori in n_l X_trini][Xra[X_trinnew_ser==1].idex]=0 X_est[i][X_test[X_test.nw_user==1].inex]=0
4.1.5 异常值处理
将customer_value_profit、ctrip_profits中的负值按0处理
将delta_price1、delta_price2、lowestprice中的负值按中位数处理
for f in flter_two: a = X_trin[].median() X_tran[f][X_train[f]<0]=a X_test[f][X_est[]<0]=a tran[f][train[f]<0]=a
4.1.6 缺失值填充
趋于正态分布的字段,使用均值填充:businessrate_pre2、cancelrate_pre、businessrate_pre;偏态分布的字段,使用中位数填充.
def na_ill(df): for col in df.clumns: mean = X_trai[col].mean() dfcol]=df[col].fillna(median) return
## 衍生变量年成交率 X_train["onear_dalate"]=_tain["odernum_onyear"]/X_tran"visinum_onyar"] X_st["onyardealae"]=X_st["orernum_neyear"]/Xtest[visitumonyear"] X_al =pd.nca([Xtin,Xtes)
#决策树检验 dt = Decsionr(random_state=666) pre= dt.prdict(X_test) pre_rob = dt.preicproa(X_test)[:,1] pre_ob
4.2 数据标准化
scaler = MinMacaer() #决策树检验 dt = DeonTreasifi(random_state=666)
5 特征筛选
5.1 特征选择-删除30%列
X_test = X_test.iloc[:,sp.get_spport()] #决策树检验 dt = DecisonreeClssifie(random_state=666) dt.fit(X_trin,y_tain) dt.score(X_tst,y_est) pre = dt.pdict(X_test) pe_rob = dt.redicproba(X_test)[:,1] pr_rob uc(pr,tpr)

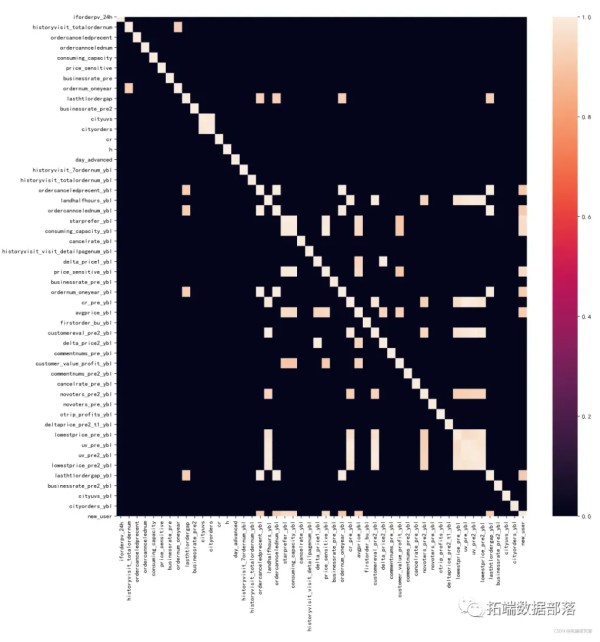
5.2 共线性/数据相关性
#共线性--严重共线性0.9以上,合并或删除 d = Xtrai.crr() d[d<0.9]=0 #赋值显示高相关的变量 pl.fufsiz=15,15,dpi200) ssheatp(d)
6 建模与模型评估
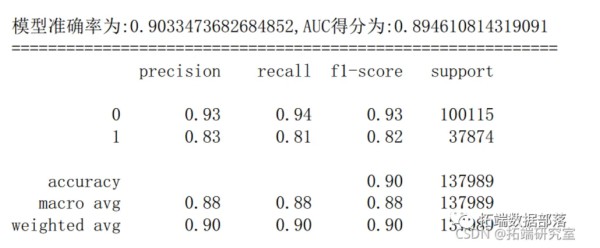
6.1 逻辑回归
y_prob = lr.preictproba(X_test)[:,1] y_pred = lr.predict(X_test fpr_lr,pr_lr,teshold_lr = metris.roc_curve(y_test,y_prob) ac_lr = metrcs.aucfpr_lr,tpr_lr) score_lr = metrics.accuracy_score(y_est,y_pred) prnt("模准确率为:{0},AUC得分为{1}".fomat(score_lr,auc_lr)) prit("="*30
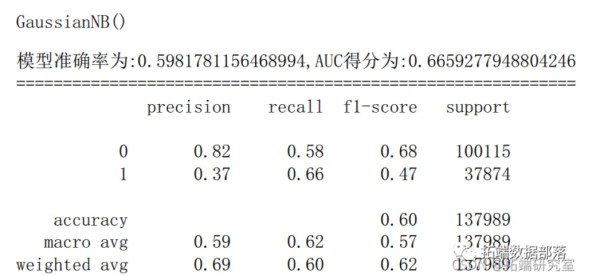
6.2 朴素贝叶斯
gnb = GasinNB() # 实例化一个LR模型 gnb.fi(trai,ytran) # 训练模型 y_prob = gn.pic_proba(X_test)[:,1] # 预测1类的概率 y_pred = gnb.preict(X_est) # 模型对测试集的预测结果 fpr_gnb,tprgnbtreshold_gb = metrics.roc_crve(ytesty_pob) # 获取真阳率、伪阳率、阈值 aucgnb = meic.aucf_gnb,tr_gnb) # AUC得分 scoe_gnb = merics.acuray_score(y_tes,y_pred) # 模型准确率
6.3 支持向量机
s =SVkernel='f',C=,max_ter=10,randomstate=66).fit(Xtrain,ytrain) y_rob = sc.decsion_untio(X_st) # 决策边界距离 y_ed =vc.redit(X_test) # 模型对测试集的预测结果 fpr_sv,tpr_vc,theshld_sv = mtris.rc_urv(y_esty_pob) # 获取真阳率、伪阳率、阈值 au_vc = etics.ac(fpr_sc,tpr_sv) # 模型准确率 scre_sv = metrics.ccuracy_sore(_tst,ypre)
6.4 决策树
dtc.fit(X_tran,_raiproba(X_test)[:,1] # 预测1类的概率 y_pred = dtc.predct(X_test # 模型对测试集的预测结果 fpr_dtc,pr_dtc,thresod_dtc= metrcs.roc_curvey_test,yprob) # 获取真阳率、伪阳率、阈值
6.5 随机森林
c = RndoForetlassiir(rand_stat=666) # 建立随机森 rfc.it(X_tain,ytrain) # 训练随机森林模型 y_rob = rfc.redict_poa(X_test)[:,1] # 预测1类的概率 y_pedf.pedic(_test) # 模型对测试集的预测结果 fpr_rfc,tp_rfc,hreshol_rfc = metrcs.roc_curve(y_test,_prob) # 获取真阳率、伪阳率、阈值 au_fc = meris.auc(pr_rfctpr_fc) # AUC得分 scre_rf = metrcs.accurac_scor(y_tes,y_ped) # 模型准确率
6.6 XGboost
# 读训练数据集和测试集 dtainxgbatrx(X_rai,yrain) dtest=g.DMrx(Xtest # 设置xgboost建模参数 paras{'booser':'gbtee','objective': 'binay:ogistic','evlmetric': 'auc' # 训练模型 watchlst = (dtain,'trai) bs=xgb.ran(arams,dtain,n_boost_round=500eva=watchlst) # 输入预测为正类的概率值 y_prob=bst.redict(dtet) # 设置阈值为0.5,得到测试集的预测结果 y_pred = (y_prob >= 0.5)*1 # 获取真阳率、伪阳率、阈值 fpr_xg,tpr_xgb,heshold_xgb = metricsroc_curv(test,y_prob) aucxgb= metics.uc(fpr_gb,tpr_xgb # AUC得分 score_gb = metricsaccurac_sore(y_test,y_pred) # 模型准确率 print('模型准确率为:{0},AUC得分为:{1}'.format(score_xgb,auc_xgb))

6.7 模型比较
plt.xlabel('伪阳率') plt.ylabel('真阳率') plt.title('ROC曲线') plt.savefig('模型比较图.jpg',dpi=400, bbox_inches='tight') plt.show()

6.8 重要特征
ea = pd.Sries(dct(list((X_trclumsfc.eatre_imortancs_)))) ea.srt_vlues(acedig=False fea_s = (fa.srt_vauesacnding=alse)).idex
6.9 流失原因分析
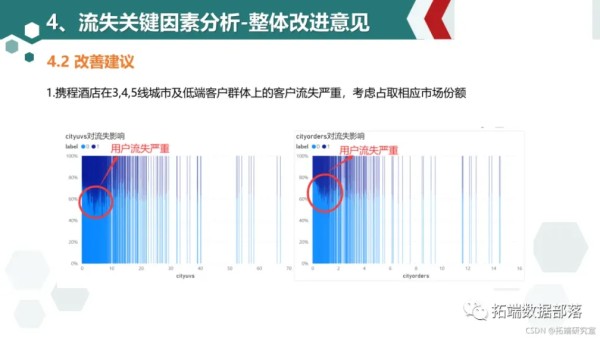
cityuvs和cityorders值较小时用户流失显著高于平均水平,说明携程平台小城市的酒店信息缺乏,用户转向使用小城市酒店信息较全的竞品导致用户流失访问时间点在7点-19点用户流失比例高与平均水平:工作日推送应该避开这些时间点
酒店商务属性指数在0.3-0.9区间内用户流失大于平均水平,且呈现递增趋势,说明平台商务指数高的酒店和用户期望有差距(价格太高或其他原因?), 商务属性低的用户流失较少
一年内距离上次下单时长越短流失越严重,受携程2015年5月-2016年1月爆出的负面新闻影响较大,企业应该更加加强自身管理,树立良好社会形象
消费能力指数偏低(10-40)的用户流失较严重,这部分用户占比50%应该引起重视
价格敏感指数(5-25)的人群流失高于平均水平,注重酒店品质
用户转化率,用户年订单数,近1年用户历史订单数越高,24小时内否访问订单填写页的人群比例越大流失越严重,需要做好用户下单后的追踪体验, 邀请填写入住体验,整理意见作出改进
提前预定天数越短流失越严重用户一年内取消订单数越高流失越严重
6.10 建议:
用户易受企业负面新闻影响,建议企业勇于承担社会责任,加强自身管理,提高公关新闻处理时效性,树立品牌良好形像
在节假日前2-3周开始热门景点酒店推送
做好酒店下单后的追踪体验,邀请填写入住体验,并整理用户意见作出改进
7 客户画像
7.1 建模用户分类
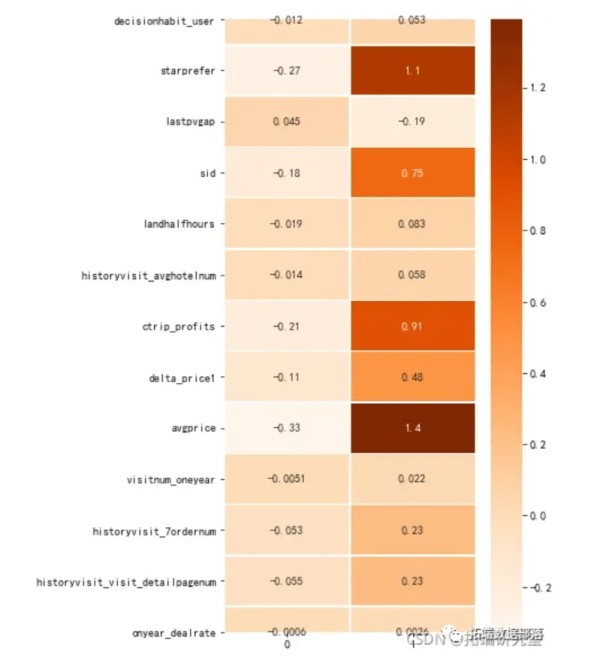
# 用户画像特征 user_feature = ["decisiohabit_user,'starprefer','lastpvgap','sid', 'lernum",'historyvisit_visit_detaipagenum', "onyear_dealrat ] # 流失影响特征 fea_lis = ["cityuvs", "cityorders", "h", "businessrate_pre2" # 数据标准化 Kmeans方法对正态分布数据处理效果更好 scaler = StanardScalr() lo_atribues = pdDatarame(scr.fittransfrm(all_cte),columns=all_ce.coluns) # 建模分类 Kmens=Means(n_cluste=2,rndom_state=0) #333 Keans.fi(lot_attributes # 训练模型 k_char=Kmenscluster_centers_ # 得到每个分类 plt.figure(figsize=(5,10))

7.2 用户类型占比
types=['高价值用户','潜力用户'] ax.pie[1], raius=0.,colors='w') plt.savefig(用户画像.jpg'dpi=400, box_inchs='tigh')
7.3 高价值用户分析
占比19.02,访问频率和预定频率都较高,消费水平高,客户价值大,追求高品质,对酒店星级要求高,客户群体多集中在老客户中,
建议:
多推荐口碑好、性价比高的商务酒店连锁酒店房源吸引用户;
在非工作日的11点、17点等日间流量小高峰时段进行消息推送。
为客户提供更多差旅地酒店信息;
增加客户流失成本:会员积分制,推出会员打折卡
7.4 潜力用户分析
占比:80.98% 访问频率和预定频率都较低,消费水平较低,对酒店星级要求不高,客户群体多集中在新客户中,客户价值待挖掘 建议:
因为新用户居多,属于潜在客户,建议把握用户初期体验(如初期消费有优惠、打卡活动等),还可以定期推送实惠的酒店给此类用户,以培养用户消费惯性为主;
推送的内容应多为大减价、大酬宾、跳楼价之类的;
由于这部分用户占比较多,可结合该群体流失情况分析流失客户因素,进行该群体市场的开拓,进一步进行下沉分析,开拓新的时长。
相关文章
Python中利用遗传算法探索迷宫出路
本文探讨了如何利用Python和遗传算法解决迷宫问题。迷宫建模通过二维数组实现,0表示通路,1为墙壁,'S'和'E'分别代表起点与终点。遗传算法的核心包括个体编码(路径方向序列)、适应度函数(评估路径有效性)、选择、交叉和变异操作。通过迭代优化,算法逐步生成更优路径,最终找到从起点到终点的最佳解决方案。文末还展示了结果可视化方法及遗传算法的应用前景。
基于 Python 哈希表算法的局域网网络监控工具:实现高效数据管理的核心技术
在当下数字化办公的环境中,局域网网络监控工具已成为保障企业网络安全、确保其高效运行的核心手段。此类工具通过对网络数据的收集、分析与管理,赋予企业实时洞察网络活动的能力。而在其运行机制背后,数据结构与算法发挥着关键作用。本文聚焦于 PHP 语言中的哈希表算法,深入探究其在局域网网络监控工具中的应用方式及所具备的优势。
员工电脑监控场景下 Python 红黑树算法的深度解析
在当代企业管理范式中,员工电脑监控业已成为一种广泛采用的策略性手段,其核心目标在于维护企业信息安全、提升工作效能并确保合规性。借助对员工电脑操作的实时监测机制,企业能够敏锐洞察潜在风险,诸如数据泄露、恶意软件侵袭等威胁。而员工电脑监控系统的高效运作,高度依赖于底层的数据结构与算法架构。本文旨在深入探究红黑树(Red - Black Tree)这一数据结构在员工电脑监控领域的应用,并通过 Python 代码实例详尽阐释其实现机制。
基于 Python 迪杰斯特拉算法的局域网计算机监控技术探究
信息技术高速演进的当下,局域网计算机监控对于保障企业网络安全、优化资源配置以及提升整体运行效能具有关键意义。通过实时监测网络状态、追踪计算机活动,企业得以及时察觉潜在风险并采取相应举措。在这一复杂的监控体系背后,数据结构与算法发挥着不可或缺的作用。本文将聚焦于迪杰斯特拉(Dijkstra)算法,深入探究其在局域网计算机监控中的应用,并借助 Python 代码示例予以详细阐释。
如何在Python下实现摄像头|屏幕|AI视觉算法数据的RTMP直播推送
本文详细讲解了在Python环境下使用大牛直播SDK实现RTMP推流的过程。从技术背景到代码实现,涵盖Python生态优势、AI视觉算法应用、RTMP稳定性及跨平台支持等内容。通过丰富功能如音频编码、视频编码、实时预览等,结合实际代码示例,为开发者提供完整指南。同时探讨C接口转换Python时的注意事项,包括数据类型映射、内存管理、回调函数等关键点。最终总结Python在RTMP推流与AI视觉算法结合中的重要性与前景,为行业应用带来便利与革新。
基于 Python 哈希表算法的员工上网管理策略研究
于当下数字化办公环境而言,员工上网管理已成为企业运营管理的关键环节。企业有必要对员工的网络访问行为予以监控,以此确保信息安全并提升工作效率。在处理员工上网管理相关数据时,适宜的数据结构与算法起着举足轻重的作用。本文将深入探究哈希表这一数据结构在员工上网管理场景中的应用,并借助 Python 代码示例展开详尽阐述。
Python下的毫秒级延迟RTSP|RTMP播放器技术探究和AI视觉算法对接
本文深入解析了基于Python实现的RTSP/RTMP播放器,探讨其代码结构、实现原理及优化策略。播放器通过大牛直播SDK提供的接口,支持低延迟播放,适用于实时监控、视频会议和智能分析等场景。文章详细介绍了播放控制、硬件解码、录像与截图功能,并分析了回调机制和UI设计。此外,还讨论了性能优化方法(如硬件加速、异步处理)和功能扩展(如音量调节、多格式支持)。针对AI视觉算法对接,文章提供了YUV/RGB数据处理示例,便于开发者在Python环境下进行算法集成。最终,播放器凭借低延迟、高兼容性和灵活扩展性,为实时交互场景提供了高效解决方案。
探秘文件共享服务之哈希表助力 Python 算法实现
在数字化时代,文件共享服务不可或缺。哈希表(散列表)通过键值对存储数据,利用哈希函数将键映射到特定位置,极大提升文件上传、下载和搜索效率。例如,在大型文件共享平台中,文件名等信息作为键,物理地址作为值存入哈希表,用户检索时快速定位文件,减少遍历时间。此外,哈希表还用于文件一致性校验,确保传输文件未被篡改。以Python代码示例展示基于哈希表的文件索引实现,模拟文件共享服务的文件索引构建与检索功能。哈希表及其分布式变体如一致性哈希算法,保障文件均匀分布和负载均衡,持续优化文件共享服务性能。
目录
4.1.5 异常值处理 4.1.6 缺失值填充 4.2 数据标准化 5 特征筛选 5.1 特征选择-删除30%列 5.2 共线性/数据相关性 6 建模与模型评估 6.1 逻辑回归 6.2 朴素贝叶斯 6.3 支持向量机 6.4 决策树 6.5 随机森林 6.6 XGboost 6.7 模型比较 6.8 重要特征 6.9 流失原因分析 6.10 建议: 7 客户画像 7.1 建模用户分类 7.2 用户类型占比 7.3 高价值用户分析 7.4 潜力用户分析网址:【视频】支持向量机算法原理和Python用户流失数据挖掘SVM实例(下) http://c.mxgxt.com/news/view/1153093
相关内容
一文弄懂数据挖掘的十大算法,数据挖掘算法原理讲解关于数据挖掘的十种算法原理讲解
大数据挖掘算法实战:如何挖掘海量数据中的隐藏价值
数据挖掘 用什么软件
数据挖掘算法有哪些
从小白视角理解『数据挖掘十大算法』
钉钉杯常用数据挖掘算法总结
数据挖掘是对业务和用户的理解
数据挖掘经典算法PrefixSpan的一个简单Python实现
如何为余景天做数据挖掘
随便看看
最新实时动态
- 高诗岩这10年下来到底挣了...@烽火台高连远烟的动态
- 一天签下4.48亿合同,布克唐斯的女经纪人能抽多少佣金?数字惊人
- 赛季刚开始,谁能想到杰伦...@萌仔仔分享生活的动态
- 郭艾伦转会有变化!朱芳雨出手,广东插手陈盈骏转会引发连锁反应
- 96黄金一代最大单个合...@韦观Maxwell的动态
- 肥皂剧终结!姆巴佩将续约3年!皇马决定放弃,或压哨签米兰核心
- 解约金8053万!曼联锁定英超顶级中场,22岁高潜力中卫或同步来投
- 德转官宣!上港仅花130万续约奥斯卡,本人已同意!
- NBA球星收入有多夸张?塔图姆新合同曝光,每年仅缴税就2.7亿
- LPL新赛季大变天!顶尖选手合同集体到期,左手TS或遭整个LPL疯抢
热点实时动态
- 11855
- 7365
- 7175
- 7013
- 6981
- 6691
- 6255
- 6078
- 6077
- 6057

