Spark中的资源调度
版权声明:
本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《 阿里云开发者社区用户服务协议》和 《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写 侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Spark中涉及的资源调度可以分为4层:
YARN对不同SparkApplication(SparkContext)的调度 同一个SparkAppliction内不同资源池(pool)之间的调度 同一个SparkAppliction内同一个资源池(pool)内不同TaskSetManager的调度 同一个SparkAppliction内同一个资源池(pool)内同一个TaskSetManager内的Task调度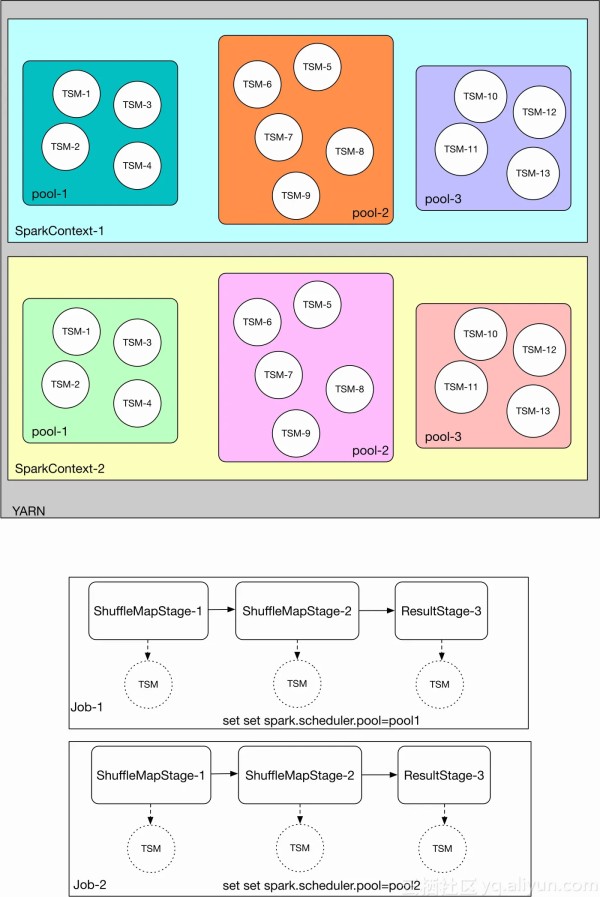
前置
为啥需要资源调度
当用户提交作业,Spark内部的执行流程如下图:

Spark上层的SQL/Streaming等最终都会生成RDD到底层SparkCore执行。如上图所示当RDD执行一个action类型的算子(如collect)会触发一个Job的提交到DAGScheduler,DAGScheduler会将Job拆成Stage(根据shuffle来拆分Stage)形成一个DAG,拆分的Stage之间有依赖关系,最后执行的是ResultStage,ResuStage之前会依赖ShuffleMapStage等,每个Stage的执行都需要先将它的父Stage执行完成。
当提交一个Stage执行时,Spark会给Stage生成一个对应的TaskSetManager,TaskSetManager用来管理该Stage中所有的Task。
当有多个用户同时提交作业到同一个SparkApplication时(如通过beeline客户端提交SQL到SparkThriftServer,SparkThriftServer就是一个常驻的SparkApplication),SparkApplication里面最终会有很多的TaskSetManager产生,那如何对这些TaskSetManager进行调度呢,比如当有资源空闲的时候选择哪个TaskSetManager先执行呢?当选择了某个TaskSetManager后,如何选择该TaskSetManager里面的某个Task优先执行呢?这里面就涉及了资源调度的问题。
Spark调度器
参考: Spark调度文档
Spark调度器是指在同一个SparkApplication内Spark如何对TaskSetManager(图中简写TSM)进行调度,以及同一个TaskSetManager内的Task如何调度。
Spark内部支持两种类型的资源调度
场景 调度类型 备注 pool之间 FIFO/FAIR 可以通过spark.scheduler.mode来配置 pool内 FIFO/FAIR 若spark.scheduler.mode=FIFO,则pool内只能是FIFO,若spark.scheduler.mode=FAIR,pool内可以通过fairscheduler.xml来配置,可以为FIFO或者FAIR FIFO先入先出,后面的TaskSetManager要等比自己先提交的TaskSetManager执行完了才能执行,如果先提交的TaskSetManager要很长很长时间才能执行完,也只能等待。如第一个人提交了一个大SQL,第二个人提交了一个很小的SQL(可能几秒就运行完了),也是需要等待大SQL有资源空出了才能执行。 FAIR
公平调度,会根据fairscheduler.xml里面的相关配置来进行调度,如weight/minShare等配置信息进行调度。即使前面有个大SQL运行,小SQL也是有机会获取到资源运行(根据实际的配置信息),不需要等待。
配置使用流程
启动SparkApplication可以执行pool之间的调度策略,通过spark.scheduler.mode来指定(默认FIFO) 如果是使用FAIR时,用户启动前还需要提供资源池的配置信息(fairscheduler.xml),参考如下
<allocations> <pool name="production"> <schedulingMode>FAIR</schedulingMode> <weight>1</weight> <minShare>2</minShare> </pool> <pool name="test"> <schedulingMode>FIFO</schedulingMode> <weight>2</weight> <minShare>3</minShare> </pool> </allocations> 如果是FAIR,用户提交作业时可指定pool名称,可通过设置spark.scheduler.pool来指定,默认是default 如果是FAIR,提交完后Spark会通过FAIR进行pool之间的调度,以及pool内部通过fairscheduler.xml的配置策略调度(如上面xml中test pool内部使用FIFO来调度,而production pool内部使用FAIR来调度)
UI显示
FIFO
FAIR
4层调度
SparkApplication调度
用户提交SparkApplication到YARN中运行,是通过YARN的队列(Queue)进行调度。提交SparkApplication时可以通过参数spark.yarn.queue来指定该SparkApplication提交到YARN的哪个队列(该队列的具体资源配置可参考YARN官方文档( FAIR, Capacity)
pool之间的调度
同一个SparkApplication内部可参考上面前置->配置使用流程小节。
通过spark.scheduler.mode来设置启动SparkApplicaion,如果是FAIR,需要配置好fairscheduler.xml。
pool内的调度
同一个pool内部可参考上面前置->配置使用流程小节。
当spark.scheduler.mode=FIFO,pool内部只能默认使用FIFO调度,用户也无需配置相关xml;
当spark.scheduler.mode=FAIR,需要用到前面的fairscheduler.xml,通过spark.scheduler.pool来设置提交到哪个pool
TaskSetManager内的Task调度
TaskSetManager是pool内调度的单元,当pool内部根据调度算法获取到了某个TaskSetManager,然后还需要从这个TaskSetManager获取到一些Task来实际运行,这个地方就是TaskSetManager内部的Task调度。
Task调度主要是考虑locality,即对于某个被调度的executor,根据
ROCESS_LOCAL -> NODE_LOCAL -> NO_PREF -> RACK_LOCAL ->ANY的顺序从TaskSetManager中选择Task去这个executor上面执行。
测试
测试SQL
SQL 备注 大SQL 整个SQL执行完耗费时间长 小SQL 整个SQL执行完耗费时间短测试环境
使用SparkThriftServer进行测试,fairscheduler.xml使用上面的配置。
测试场景
场景 pool间调度 pool内调度 场景1 FIFO 无 场景2 FAIR 大SQL和小SQL分别提交到各自pool 场景3 FAIR 大SQL和小SQL提交到同一个pool(FIFO/FAIR)备注: 都是先提交大SQL,然后再提交小SQL
测试结果
场景1小SQL等待大SQL有资源空出(如最后大SQL只剩余几个Task在跑了)才能执行,即需要等待 场景2
小SQL不需要等待大SQL空出资源,当大SQL在执行的过程中,小SQL有机会能根据FAIR算法获取到资源执行。 场景3
当pool内部调度是FIFO时,小SQL需要等待大SQL资源空出
当pool内部调度是FAIR时,当大SQL在执行的过程中,小SQL有机会能根据FAIR算法获取到资源执行。
相关实践学习
基于EMR Serverless StarRocks一键玩转世界杯
快速掌握阿里云 E-MapReduce
E-MapReduce 是构建于阿里云 ECS 弹性虚拟机之上,利用开源大数据生态系统,包括 Hadoop、Spark、HBase,为用户提供集群、作业、数据等管理的一站式大数据处理分析服务。 本课程主要介绍阿里云 E-MapReduce 的使用方法。
网址:Spark中的资源调度 http://c.mxgxt.com/news/view/1218858
相关内容
利用动态资源分配优化Spark应用资源利用率Ion Stoica:做成Spark和Ray两个明星项目的秘笈从中我们可以通过第一手资料了解到发起Spark和Ray、成
基于Spark的音乐专辑数据处理与分析 spark歌曲
七成员经历重重考验 TEAM SPARK火星团正式出道
StarRocks资源调度
Ion Stoica与分布式计算的双星:Spark与Ray的成功之道
推热转,Karina和Giselle直播跳《Dopamine》、《Up》、《Bored》、《Spark》
华为公司取得资源调度专利,提高FPGA设备的资源利用率
dataworks的独享调度资源组 与独享数据集成资源组的区别是什么?
DataWorks创建独享数据集成资源、独享调度资源组的功能有哪些?
随便看看
最新实时动态
- 曲风百变的气质古风歌手,这五首歌非常好听,第一百听不厌!
- 古风歌手有哪些 2017古风男女歌手排行榜介绍
- 十大最好听的经典古风歌曲 《牵丝戏》第一,第九被抖音带火(3)
- 盘点国内近几年古风音乐!
- 最火的古风歌曲排行榜,一次听遍古风神曲
- 古风歌集!14首经典中文古风曲带你穿越时空
- 十大最好听的古风歌曲,回味经典,享受古风之美
- 三首超燃的古风歌曲,听到前奏,仿佛就身处于豪情万丈的江湖
- 100首神仙级古风歌曲戏腔音乐排行榜
- 10首古风歌曲推荐
热点实时动态
- 12031
- 7397
- 7202
- 7041
- 7007
- 6718
- 6283
- 6105
- 6105
- 6087

