信息增益比
以信息增益作为划分训练数据集的特征,存在偏向于选择取值较多的特征的问题,使用信息增益比可以对这一问题进行校正。

以给定的集合D为例,计算信息增益比。
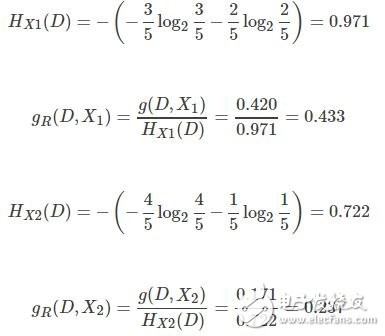
根据信息增益比,选择X1作为分类的最优特征。
C4.5决策树在生成的过程中,根据信息增益比来选择特征。
3.实现一个决策树
3.1创建或载入数据集
首先需要创建或载入训练的数据集,第一节用的是创建数据集的方法,不过更常用的是利用open()函数打开文件,载入一个数据集。
3.2生成决策树
决策树一般使用递归的方法生成。
编写递归函数有一个好习惯,就是先考虑结束条件。生成决策树结束的条件有两个:其一是划分的数据都属于一个类,其二是所有的特征都已经使用了。在第二种结束情况中,划分的数据有可能不全属于一个类,这个时候需要根据多数表决准则确定这个子数据集的分类。
在非结束的条件下,首先选择出信息增益最大的特征,然后根据其分类。分类开始时,记录分类的特征到决策树中,然后在特征标签集中删除该特征,表示已经使用过该特征。根据选中的特征将数据集分为若干个子数据集,然后将子数据集作为参数递归创建决策树,最终生成一棵完整的决策树。
#多数表决法则
def majorityCnt(classList):
print classList
classCount = {}
for vote in classList: #统计数目
if vote not in classCount.keys(): classCount[vote] = 0
classCount += 1
sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return classCount[0][0]
# 生成决策树
def create_tree(dataSet, labels):
labelsCloned = labels[:]
classList = [example[-1] for example in dataSet] #[yes,yes,no,no,no]
if classList.count(classList[0]) == len(classList): #只有一种类别,则停止划分
return classList[0]
if len(dataSet[0]) == 1: #没有特征,则停止划分
return majorityCnt(classList)
#print dataSet
bestFeat = choose_best_feature(dataSet)
bestFeatLabel = labelsCloned[bestFeat] #最佳特征的名字
myTree = {bestFeatLabel:{}}
del(labelsCloned[bestFeat])
featValues = [example[bestFeat] for example in dataSet] #获取最佳特征的所有属性
uniqueVals = set(featValues)
for value in uniqueVals: #建立子树
subLabels = labelsCloned[:] #深拷贝,不能改变原始列表的内容,因为每一个子树都要使用
myTree[bestFeatLabel][value] = create_tree(split_data_set(dataSet, bestFeat, value), subLabels)
return myTree
生成的决策树如下所示:
3.3使用决策树
使用决策树对输入进行分类的函数也是一个递归函数。分类函数需要三个参数:决策树,特征列表,待分类数据。特征列表是联系决策树和待分类数据的桥梁,决策树的特征通过特征列表获得其索引,再通过索引访问待分类数据中该特征的值。
def classify(tree, featLabels, testVec):
firstJudge = tree.keys()[0]
secondDict = tree[firstJudge]
featIndex = featLabels.index(firstJudge) #获得特征索引
for key in secondDict: #进入对应的分类集合
if key == testVec[featIndex]: #按特征分类
if type(secondDict[key]).__name__ == 'dict': #如果分类结果是一个字典,则说明还要继续分类
classLabel = classify(secondDict[key], featLabels, testVec)
else: #分类结果不是字典,则分类结束
classLabel = secondDict[key]
return classLabel
3.4保存或者载入决策树
生成决策树是比较花费时间的,所以决策树生成以后存储起来,等要用的时候直接读取即可。
def store_tree(tree, fileName): #保存树
import pickle
fw = open(fileName, 'w')
pickle.dump(tree, fw)
fw.close()
def grab_tree(fileName): #读取树
import pickle
fr = open(fileName)
return pickle.load(fr)
4.决策树可视化
网址:信息增益比 http://c.mxgxt.com/news/view/1305926
相关内容
海港人寿启明星龙腾版增额终身寿险基本信息介绍,海港人寿终身寿险收益有多少?做公益不够公开透明?多家基金会负责人谈信息披露
中银香港(02388)首季净息收入同比增加9.4%至98.95亿港元
机场追星利益链,贩卖明星信息涉嫌侵犯公民个人信息罪
民政部正式发布《公益慈善捐助信息公开指引》
启明信息(002232)
乐视网新增一条被执行人信息
自如“增益租” 卖装修还放贷?
机场追星利益链:明星私人信息明码标价 微信号88元
吴秀波新增股权冻结信息 冻结数额4950万元
随便看看
最新实时动态
- 后卫阵容强大!胡明轩、赵继伟等多位明星球员闪耀舞台
- NBA全明星正赛前瞻:东部明星队VS西部明星队
- 埃及明星赛程时间表
- 明星足球队游戏
- 动荡!3大球星去向新动态!威少欧文恐换队,字母哥被盯上了
- 4换1!火箭队可追23+4+7明星?放走范弗里特,首发阵容火力升级
- 哈登重返全明星连创纪录:追平库里现役第四 连晒多条海报兴奋庆祝
- 快船3消息!全新阵容被看好,哈登更新动态,西蒙斯出海钓鱼
- 利物浦2024
- 2025 NBA交易截止日:明星球员的命运与交易市场的变局
热点实时动态
- 12101
- 7427
- 7231
- 7071
- 7037
- 6746
- 6311
- 6133
- 6133
- 6114

