StarRocks 2.1 新版本特性介绍
各位 StarRocks 的新老用户:
StarRocks 近期发布了 2.1 版本,核心更新有支持 Apache Iceberg 外表、发布 Pipeline 执行引擎、支持多达 10000 列的表、优化首次 Scan 和 Page Cache 的性能、支持 SQL 指纹等。
以下是详细介绍,欢迎您升级使用、多多反馈!
支持 Apache Iceberg 外表(公测中)
Apache Iceberg 是目前最为流行的构建数据湖的方案之一。在支持了 Hive 外表查询之后,StarRocks 也支持了直接查询 Apache Iceberg 数据湖上的数据,让用户在无需导入数据的情况下,就能实现对数据湖的极速分析。
在 TPC-H 100G 测试集上,StarRocks 通过 CBO 优化器、向量化执行和 C++ Native 执行等优化,查询性能是 Trino (PrestoSQL) 的 3 - 5 倍。
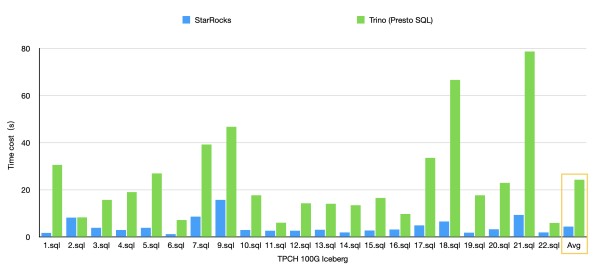
后续,我们会进一步优化查询 Apache Iceberg 数据湖的性能,同时也会实现查询 Apache Hudi 等其他数据湖方案的功能。
发布 Pipeline 执行引擎(公测中)
执行引擎在多核调度方面,原有任务模型是采用线程调度,存在两个显著问题:一,在高并发查询场景下,数据依赖和 IO 操作的阻塞会引起较多上下文切换,导致较高的调度代价;二,复杂查询的并行度设置过于复杂。
新发布的 Pipeline 执行引擎,采用更高效的协程调度机制,并且原有数据依赖和 IO 操作采用了异步化执行,降低了上下文切换的代价。在高并发场景下,部分查询性能提升为原来的 2 倍,CPU 利用率也显著提升;在 SSB、TPCH 和 TPCDS 测试集上,总体性能也有不错的提升。同时还实现了查询并行度的自适应设置,您无需再手动设置并行度变量 parallel_fragment_exec_instance_num 。
支持多达 10000 列的表
在传统的数仓模型建设中,往往会建立一些大宽表以简化使用和优化查询性能。尤其是在用户画像等场景中,几百上千列的宽表也比较常见,一些超大客户会使用几千列的表。但在导入几千列的大数据(几亿行)后,特别是还有大字符串的场景,原有按整行 Compaction 的方式会占用大量内存,很容易触发 OOM,并且 Compaction 速度也变慢很多。
新版本重构了 Compaction,按列分组分批进行多版本数据的 merge,并且优化了对大字符串的支持,减少了内存的使用。最终,在多达 10000 列表的大数据量导入场景下,内存节省了数 10 倍,Compaction 性能也提升为原来的 3 倍。
优化首次 Scan 和 Page Cache 的性能
在做大数据分析时,一些冷数据需要从磁盘读取(首次 Scan),一些热数据则可以直接从内存读取,两种场景下的查询性能可能会相差几倍甚至几十倍,核心原因是磁盘的随机 IO。StarRocks 通过减少文件数量、索引懒加载、调整文件结构等,减少随机 IO,提升了首次 Scan 的性能,尤其在 HDD 环境中,性能提升明显。
对于 SSB-100G 测试集中几个首次 Scan 对查询性能影响较大的 SQL(如 Q2.1/Q3.1/Q3.2/Q4.1),在有首次 Scan 的情形时,其查询性能提升为原来的 2~3 倍。
同时,StarRocks 也优化了自身的 Page Cache 策略,一些场景下会直接存放原始数据,无需经过 Bitshuffle 编码。因此在读取 Page Cache 数据时也无需额外解码,进而大大提升了查询效率。
支持 SQL 指纹
SQL 指纹是指对同一类 SQL 计算出的一个 MD5 值,其中,同一类 SQL 是指“规范化后只有常量不同的 SQL 文本”。通过汇总统计分析 SQL 指纹及相关信息,我们就能够很方便地了解有哪些类型的 SQL、它们出现的频率/消耗的资源/处理的时长等,从而可以对消耗资源多且不合理的 SQL ,优先进行高效的分析优化。
SQL 指纹主要被用于慢查询优化、系统资源使用(CPU/内存/磁盘读写 等)优化。比如,如果发现集群的 CPU/内存使用不太高、但磁盘使用经常打满时,可以统计磁盘读占比最高的一些 SQL 指纹,再进一步分析具体 SQL 读磁盘的合理性,就可以找到一些优化点。
其他优化
公测中的新功能支持字符串最大长度为 1MB:在一些复杂的业务和场景中,JSON 等 Schema-less 分析经常会被用到,1MB 的字符串存储能够满足绝大多数场景,结合相关函数,能很好地满足此类分析需求。
支持 CTAS(CREATE TABLE AS SELECT)语法:不再需要事先建表,查询数据即可完成 ETL 操作并导入数据到新表中;结合一些调度,就可以轻松实现轻量级的数仓建模。
去除了 JSON 导入中单个 JSON 文件不超过 100MB 大小的限制,并优化了 JSON 导入性能:让您可以轻松导入大 JSON 文件,以及轻松对接大流量的 Kafka 数据。
主键模型(Primary Key Model)支持变更表结构(Schema Change)。
支持建表语句的时间戳字段定义为 DEFAULT CURRENT_TIMESTAMP。
新增函数 ANY_VALUE、ARRAY_REMOVE、哈希函数 SHA2。
支持 Hive 的存储格式为 CSV,优化了通过外表方式读取 Hive 数据的性能。
支持导入带有多个分隔符的 CSV 文件。
优化 Bitmap Index 性能。
网址:StarRocks 2.1 新版本特性介绍 http://c.mxgxt.com/news/view/198399
相关内容
1024,我们干了点儿大事简略明星介绍
超快速介绍自己的新专辑
明星介绍
奥特曼十兄弟介绍
明星自我介绍4篇
班级小明星自我介绍(11篇)
明星自我介绍(八篇)
怎么会有人直播间介绍产品都介绍的这么有趣啊!
明星培养计划(人物介绍)
随便看看
最新实时动态
- 《今天开始做明星》免费在线观看高清完整版
- 明星的穿搭“神”助攻竟是TA
- 动漫明星大乱斗无敌版
- 明星穿衣风格图片 明星衣服穿搭图片欣赏(2)
- 17《动漫明星》 课件 辽海版美术三年级下册.pptx
- 我最喜欢的卡通明星.doc
- 震惊!这些明星的动漫形象竟然比真人更吸睛,快来get同款头像!
- 我最喜欢的卡通明星作文350字
- 我喜欢的卡通明星三年级作文400字
- 这个明星的动漫形象火了!你也能轻松拥有
热点实时动态
- 12060
- 7412
- 7217
- 7056
- 7024
- 6732
- 6297
- 6120
- 6120
- 6103

