Nature:人类基因组计划20年, 明星基因大放异彩,生物网络亟待探索
发布时间:2025-04-30 17:26

导语
人类基因组计划(Human Genome Project, HGP)是一项规模宏大、跨国跨学科的科学探索工程。其宗旨在于测定组成人类染色体(指单倍体)中所包含的由30亿个碱基对所组成的核苷酸序列,从而绘制人类基因组图谱、辨识其载有的基因及其序列,达到破译人类遗传信息的最终目的。2021年2月11日,在人类基因组图谱发布20周年之际,Nature刊登的一篇网络科学学者Albert-László Barabási等人的评论文章,分析了自2001年以来基因组研究领域的发表刊物、研发药物与人类疾病的影响关系,旨在为未来基因组研究提供新的视角。

Alexander J. Gates, Deisy Morselli Gysi, Manolis Kellis, Albert-László Barabási | 作者
胡一冰 | 译者
赵雨亭、刘培源 | 审校
邓一雪 | 编辑
1. 基因组计划研究趋势
人类基因组图谱第一版 [1,2] 发表20周年是一个契机,让我们能回溯该项目如何促进了人类疾病的基因根源研究、如何改变了药物研发以及如何协助修正我们对基因本身的理解。 在这里,我们根据现有资料预测关于人类基因组未来研究的影响和趋势。研究者们结合多个数据集来量化已经发现并被发表的不同类型的遗传因素 (genetic element) ;以及这些年来,发现和发表的模式是如何变化的。分析利用的数据具体包括38546个RNA转录物 (transcripts) 、约100万个单核苷酸多态性 (Single Nucleotide Polymorphisms, SNPs) 、1660种有记载的受遗传影响的人类疾病、7712种已批准和试验的药物和704515篇1900至2017年间的科研著作。 图1. Nature和Science为纪念HGP20周年的特别封面
图1. Nature和Science为纪念HGP20周年的特别封面 研究结果强调了人类基因组计划(Human Genome Project , HGP)及其全面的蛋白质编码基因清单如何开辟展示基因组非编码部分功能的新时代,并为未来的医药开发铺平道路。关键的是,研究人员绘制亚细胞结构 (cellular building blocks) 之间的相互作用图时,研究结果可追溯到生物学系统层视图与传统单基因视图的出现。 本项分析也存在局限性。例如,学界对部分基因的起始位点、终止位点,甚至是某些基因的确切编码序列都没有达成共识 [3] 。一些基因元件使用多种命名规则,因此有时研究人员无法将它们统一起来。此外,有些作者没有将学术著作和基因序列之间的联系添加到数据库中。最后,考虑到文章的发表和进入我们使用的数据库之间可能会存在时间差,我们用来构造相互作用图表的数据截止于2017年。然而,我们并不认为这些问题会影响我们在基因组计划研究中所发现的整体趋势。当我们归一化同期生物学出版物的增长数目时,趋势仍然存在 (如图2所示) 。本项研究没有控制基因发现后的进程,但作者判断这样假设处理之下,结论依然成立。
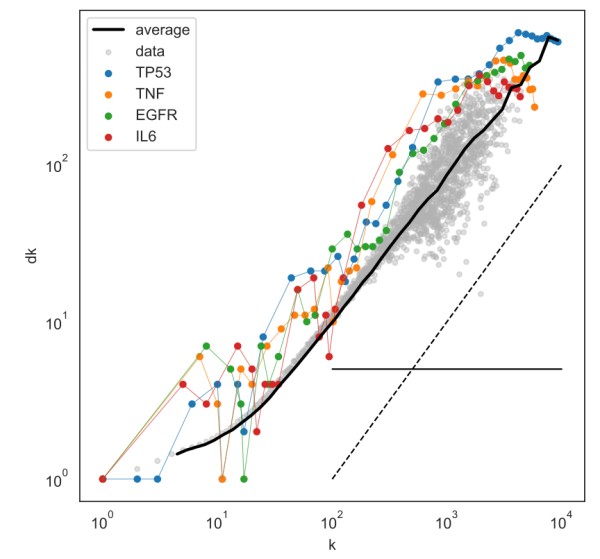 图2. 基因研究中的“偏好依附”现象 这些联系提供了人类基因组计划前后研究格局演变的快照。它表示了学术界对少数“超级明星”蛋白质编码基因的强烈关注,这可能会减少潜在的、对其它基因的研究。基因组的非蛋白质编码部分以及遗传物质和蛋白质之间的互作一直是研究的重点。事实是,药物研发更多基于少数某些蛋白质靶点。 其中一些趋势被生物学家们所熟悉,但要量化和形象化这些趋势,就必须以全新的方式研究它们。
图2. 基因研究中的“偏好依附”现象 这些联系提供了人类基因组计划前后研究格局演变的快照。它表示了学术界对少数“超级明星”蛋白质编码基因的强烈关注,这可能会减少潜在的、对其它基因的研究。基因组的非蛋白质编码部分以及遗传物质和蛋白质之间的互作一直是研究的重点。事实是,药物研发更多基于少数某些蛋白质靶点。 其中一些趋势被生物学家们所熟悉,但要量化和形象化这些趋势,就必须以全新的方式研究它们。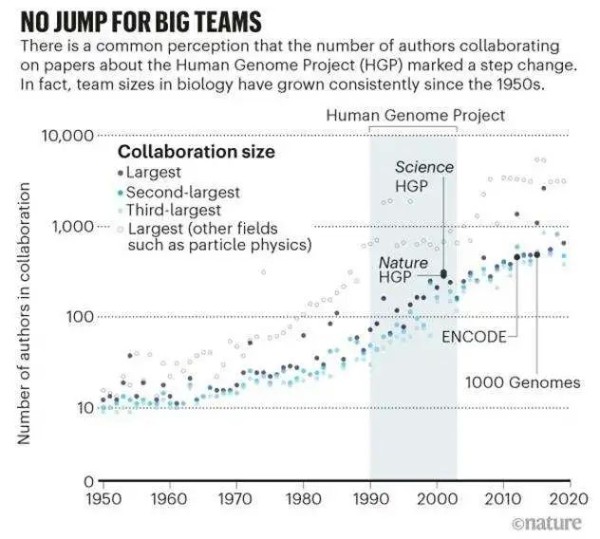 图3. 1950年至2020年基因研究合作项目成员规模变化 世界上没有可与人类基因组计划比肩的对照组。因此,不能表明上述趋势是否必然会随着人类基因组计划而出现。从计算能力的提高到复杂的排序方法的发明,种种外部因素也在这些发展中发挥了作用。唯一可以确定的是,人类基因组计划目录推动了基因革命的进行。
图3. 1950年至2020年基因研究合作项目成员规模变化 世界上没有可与人类基因组计划比肩的对照组。因此,不能表明上述趋势是否必然会随着人类基因组计划而出现。从计算能力的提高到复杂的排序方法的发明,种种外部因素也在这些发展中发挥了作用。唯一可以确定的是,人类基因组计划目录推动了基因革命的进行。2. “超级明星基因”大放异彩
学术界普遍认为,人类基因组计划是对蛋白质编码基因深入研究的开始。2001年发表的人类基因组计划草图标志着长达数十年的探索工作的结束 [1,2] 。事实上,最早的蛋白质编码基因的证据出现在1902年——即激素分泌素 (SCT基因) 的发现 [4] 。此时早于DNA结构发现50年、基因组测序普遍化75年。本项分析表明,从1990年人类基因组计划的开始到2003年完成 (2001年草图发表后) ,人类基因的发现 (或“注释”) 数量急剧增长。而在2000年代中期,这个数量突然稳定下来——约有2万个蛋白质编码基因被发现,远低于此前许多科学家提出的10万这一海量的估计数。 虽然蛋白质编码基因的发现数量进入了平台期,但在人类基因组计划开始之后,人们对单个基因功能的兴趣迅速增长。自2001年以来,每年都有1万至2万篇关于蛋白质编码基因的论文发表。 然而,科学界的兴趣主要集中在少数几个基因上。1990年以前,HBA1是研究最多的——它是编码成人血红蛋白中的一种蛋白质。从1990年起,由于CD4蛋白参与T细胞免疫且作为HIV的细胞受体,人们的注意力转移到了CD4 (结论基于累计发表的文献数量得出) 。然而,在2001年人类基因组计划序列草图之后,人们对这两个基因的兴趣与对其它基因的关注度相比就相形见绌了。一些“明星”基因——如TP53、TNF和EGFR——成为了每年数百篇论文的主题,而其它的大多数基因却很少受到关注。统计发现,2017年,1%的基因覆盖了22%的基因相关出版物主题。
图4. HGP问世前后对基因的研究情况。图中的平面标志着2001年人类基因组计划草图的公布,在其之下的长度表示为草图发表后有关基因的文章数量有关;在其之上表示先前的出版物。每个峰值底部的宽度反映了与每个基因相关的疾病数量。
当然,对具有深远生物学意义的基因进行深入研究是必需的。TP53就是一个很好的例子——它对细胞的生长和死亡至关重要,一旦它失活或变异就会导致癌症:从1976年至2017年间,9232篇学术论文提出超过50%的肿瘤序列中都发现了该基因突变。 我们的直观感受可能会认为,对同一基因了解得越多,就越有动力去探索基因组的其余部分。然而,在过去20年事实却相反:大部分的关注聚焦于少数基因。尽管在人类基因组计划草图发表十周年之际 (即2011年) [5] ,该问题就已经被广泛报道,但目前仍没有对该问题其进行实质性的修正。 之前关于人类社会网络到万维网等不同系统的研究表明,这种巨大的失衡可以用根植于社会因素的“富者越富”来解释 [6,7] 。的确,随着关于TP53的论文数量的增加,后续有关TP53的研究工作更容易获得资金、指导、工具和引用——因为这是一个安全保险的投资。在网络科学中,这种现象被称为“偏好依附 (preferential attachment) ” [7] 。事实上,我们发现关注特定基因的年度新出版物数量与先前有关该基因的文献数量成线性比例。 现在生物学面临的一个重大挑战是理清下一步研究的方向。研究人员是该是把经费、时间及精力投入到最重要或最紧迫的工作上,还是因为能可靠地获得资助和喝彩而投入到更多重复的工作上?3. “垃圾”DNA同样重要
在人类基因组计划开始之前有一场大型辩论:是否值得绘制基因组中被称为垃圾DNA (junk DNA) 或基因组暗物质的大量非编码区?在很大程度上归功于人类基因组计划,现在人们认识到,人类基因组中的大多数功能序列并不编码蛋白质。相反,是诸如 长链非编码RNA (long noncoding RNA,lncRNA) 、启动子、增强子和无数基因调控序列等元件共同作用使基因组复杂但有序地指导生命活动。这些区域的变异不会改变蛋白质,但通过扰乱控制蛋白质表达的网络来影响生命活动的进行。 人类基因组计划草图发布后,非蛋白编码元件的发现如雨后春笋般爆发。到目前为止,这种增长数量已经超过了蛋白质编码基因发现量的五倍,且仍没有放缓的迹象。同时,在本项研究所用数据集涵盖的时期 (1900至2017年) 内,关于这些调控元件的发表物数量也在增长——例如,关于调节基因表达的非编码RNA的论文数以千计。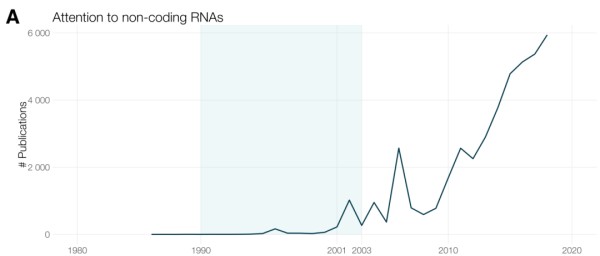 图5. 关于非编码RNA的研究呈现明显递增趋势 人类基因组计划还提供了一种编目人类遗传变异 (包括单核苷酸多态性, Single Nucleotide Polymorphism, SNP) 的方法。其它一些重大举措能大幅削减了对数千人的共同差异进行分析的成本;其中包括国际HapMap项目 [8] 和国际千人基因组计划 [9] 。这些数据集和之前的统计分析等带来了无数关于性状的全基因组关联研究 (genome-wide association studies, GWAS) ,具体如身高 [10] 、肥胖程度 [11] 和对复杂疾病 (精神分裂症等) 的易感度 [12] 。 现在每年有超过3万篇文章将单核苷酸多态性与生物性状联系起来。很大一部分关联存在于曾经被忽略的非编码区域。 细胞功能依赖于遗传物质和蛋白质之间的强弱联系。目前,已有超过30万个基因调节网络 (regulatory network) 的相互作用关系被表示出来,即蛋白质与非编码序列互作或蛋白之间互作。
图5. 关于非编码RNA的研究呈现明显递增趋势 人类基因组计划还提供了一种编目人类遗传变异 (包括单核苷酸多态性, Single Nucleotide Polymorphism, SNP) 的方法。其它一些重大举措能大幅削减了对数千人的共同差异进行分析的成本;其中包括国际HapMap项目 [8] 和国际千人基因组计划 [9] 。这些数据集和之前的统计分析等带来了无数关于性状的全基因组关联研究 (genome-wide association studies, GWAS) ,具体如身高 [10] 、肥胖程度 [11] 和对复杂疾病 (精神分裂症等) 的易感度 [12] 。 现在每年有超过3万篇文章将单核苷酸多态性与生物性状联系起来。很大一部分关联存在于曾经被忽略的非编码区域。 细胞功能依赖于遗传物质和蛋白质之间的强弱联系。目前,已有超过30万个基因调节网络 (regulatory network) 的相互作用关系被表示出来,即蛋白质与非编码序列互作或蛋白之间互作。 4. 精准助力药物开发
大约在20世纪80年代之前,大多数药物的发现源自偶然。药物分子与其分子靶点通常是未知的。2001年之前,了解药物所有蛋白质靶点的概率均小于50%。在人类基因组计划出现后,一切发生了转机。近年来,美国几乎所有获得许可的药物都能清楚知晓其蛋白质靶点。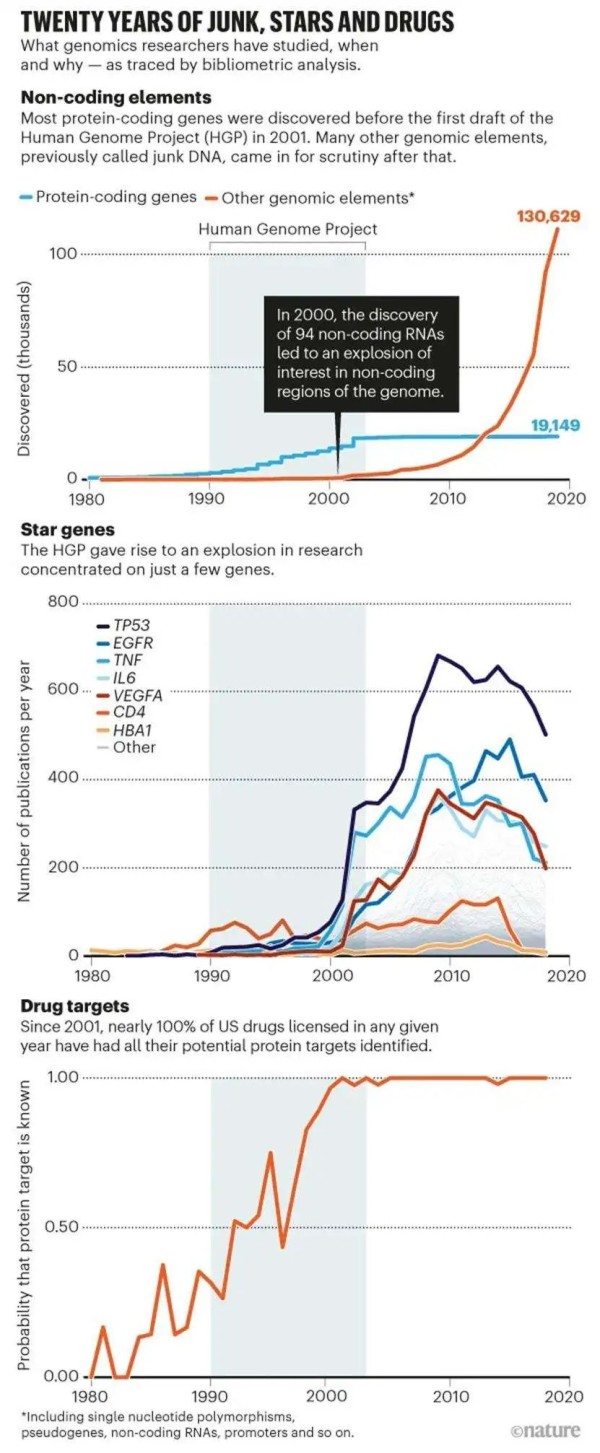
图6. 自基因组计划问世20年来“明星”基因、“垃圾”DNA和药物的研究趋势
研究同时发现,在人类基因组计划提供的约20000个可作为潜在药物靶点的蛋白质序列中,到目前为止只有约10%,即2149个是被批准的药物靶点,这表明其余90%的蛋白质组不受药理学的影响 [13] 。在我们的数据集中,实验药物将这个数字增加到3,119。同样,人们对这些问题的关注度也是不尽相同。目前批准的所有药物 (99种不同的分子) 中,有5%是以参与细胞生长和增殖的蛋白质ADRA1A为靶点。 同样地,这种“不平衡”也有其存在的理由。有一些蛋白质可能对人类健康更重要,或更倾向于成为新的药物靶点,而有些蛋白质可能无法有助于药物研发。但换言之,如果研究人员、赞助方和出版商不那么规避风险,则可能有更多的蛋白质被人们探索,从而成为新兴药物靶点。 也就是说,大多数被成功研发的药物并不直接针对个别疾病基因 [14] 。相反,它们的目标是一两个相互作用的蛋白质调控错误组成的结果。例如,我们对现有可治疗COVID-19的药物进行大规模筛查后发现,只有1%的药物有希望针对病毒蛋白,而大多数临床药物旨在用于调节人类蛋白,且这些蛋白并不直接影响SARS-CoV-2病毒的活性 [15] 。5. 生物网络逐渐明朗
综上所述,我们认为人类基因组计划比蛋白质目录本身更值得关注,因为它开创了基因组学的新时代。正如复杂系统理论所表明的那样:理解任何一个系统、对其中每个元素进行精确调查是必要的,但又远远不能止步于此。网络的复杂性恰恰来自于元素之间相互作用的多样性。经过20年以人类基因组计划为基础的研究,生物学们家现在对定义生命的网络结构和动力学有了初步了解。未来,我们也希望有更长足的进步。 参考文献:[1]Venter, J. C. et al. Science 291, 1304–1351 (2001).[2]International Human Genome Sequencing Consortium. Nature 409, 860–921 (2001).[3]Portin, P. & Wilkins, A. Genetics 205, 1353–1364 (2017).[4]Bayliss, W. M. & Starling, E. H. J. Physiol. 28, 325–353 (1902).[5]Edwards, A. M. et al. Nature 470, 163–165 (2011).[6]Bianconi, G. & Barabási, A.-L. Europhys. Lett. 54, 436 (2001).[7]Barabási, A.-L. & Albert, R. Science 286, 509–512 (1999).[8]The International HapMap Consortium. Nature 426, 789–796 (2003).[9]The 1000 Genomes Project Consortium. Nature 526, 68–74 (2015).[10]Lango Allen, H. et al. Nature 467, 832–838 (2010).[11]Speliotes, E. K. et al. Nature Genet. 42, 937–948 (2010).[12]Lencz, T. et al. Mol. Psychiatry 12, 572–580 (2007).[13]Wishart, D. S. et al. Nucleic Acids Res. 46, D1074–D1082 (2018).[14]Yildirim, M. A., Goh, K.-Il, Cusick, M. E., Barabási, A. L. & Vidal, M. Nature Biotechnol. 25, 1119–1126 (2007).[15]Gysi, D. M. et al. Preprint at https://arxiv.org/abs/2004.07229 (2020).原文链接:
https://www.nature.com/articles/d41586-021-00314-6网址:Nature:人类基因组计划20年, 明星基因大放异彩,生物网络亟待探索 http://c.mxgxt.com/news/view/903883
相关内容
巴拉巴西 Nature 刊文:人类基因组计划20年, 明星基因大放异彩,生物网络亟待探索人类基因组计划20年,如何改变了生命科学和医学?
人类基因组研究最热的十大基因,你知道几个?
宋小明团队解析明星植物基因组并搭建数据共享及分析平台
仁宽(上海)生物MGMT基因甲基化检测引物探针相关专利,可快速而精确测定人基因组MGMT基因的甲基化水平
同源基因之间的相互联系
Nature Commun|南方科大宋毅团队揭示植物塑造抗旱微生物组的遗传和生态学机制
每一件文物,都是一个记载民族血脉的基因密码;每一座博物馆,都是一座守护中华文明的基因宝库。中央电视台推出大型文博探索节目《国家宝藏》——
Nature(IF=50.5)
新冠病毒基因组演化分析和谱系划分有重要进展
随便看看
最新实时动态
- 绯闻最多的女明星图片 女明星绯闻图片
- 鹿晗关晓彤被曝已分手,更...@八大关的守静BX的动态
- 没有绯闻的明星,没有绯闻的明星算不得明星
- 陈乔恩方否认恋爱结婚绯闻,亮明单身身份,杜淳其实早有回应
- 宋智孝郑珍云确定恋爱关系,周一情侣Gary罢录?
- 北京青年报:禁止恶意炒作明星让网络环境更健康
- 泰星Mike跟Pooklook的关系获官方定论,情侣关系彻底澄清了
- 绯闻巨星 526扫兴【求月票!求点赞!求好评!】
- 金莎李智楠被曝是情侣?女方着急澄清是为何?
- 闺蜜爆料,黄晓明叶珂分手,独自产检竟是提前布局买的热搜!
热点实时动态
- 9215
- 7263
- 7085
- 6929
- 6895
- 6600
- 6166
- 5988
- 5983
- 5956

