
2024-10-14 14:19:02
如今,社交软件已经成为了我们生活必不可少的一部分。相信绝大多数人每天起来,都少不了会打开微信、QQ 刷刷朋友圈,或者打开微博、知乎看看最新热点。那么,今天我们就来看看这些软件如何建立网络社交关系。
如今,社交软件已经成为了我们生活必不可少的一部分。相信绝大多数人每天起来,都少不了会打开微信、QQ 刷刷朋友圈,或者打开微博、知乎看看最新热点。那么,今天我们就来看看这些软件如何建立网络社交关系。简单来说,网络社交关系主要分为两类:
好友关系。在微信、QQ、Facebook 等软件中,两个人可以互加好友,从而和朋友、同事、同学以及周围的人保持互动交流。粉丝关注。在微博、CSDN、知乎、Twitter 等软件中,我们可以通过关注成为其他人的粉丝,了解他/她们的最新动态。关注可以是单向的,也可以互相关注。那么对于微信、微博等这些社交软件而言,它们如何存储好友或者关注关系呢?利用这些存储的数据,我们又能够进行哪些分析、获取哪些隐藏的信息呢?
数据结构
社交网络是一个复杂的非线性结构,通常使用图(Graph)这种数据结构进行表示。
好友关系图对于微信好友这种关系,每个用户是一个顶点(Vertex);两个用户之间互加好友,就会在两者之间建立一条边(Edge)。以下是一个简单的示意图:
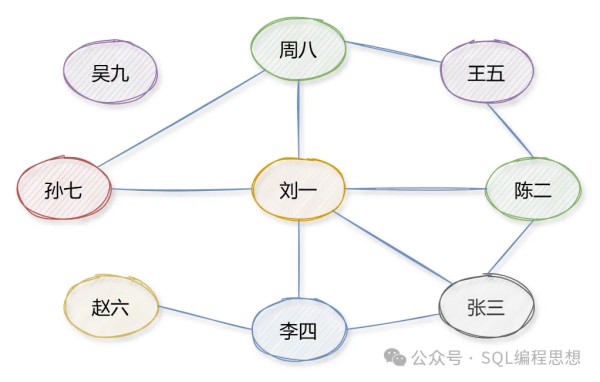
显然,好友关系是一种无向图(Undirected Graph);不存在 A 是 B 的好友,但 B 不是 A 的好友。另外,一个用户有多少个好友,连接到该顶点的边就有多少条。这个也叫做顶点的度(Degree),上图中“刘一”的度为 5(微信中表示好友数)。
对于 QQ 中的好友关系而言,还包含了额外的信息,就是好友亲密度。这种关系可以使用加权图(Weighted Graph)表示,其中的边可以分配一个数字,表示权重。
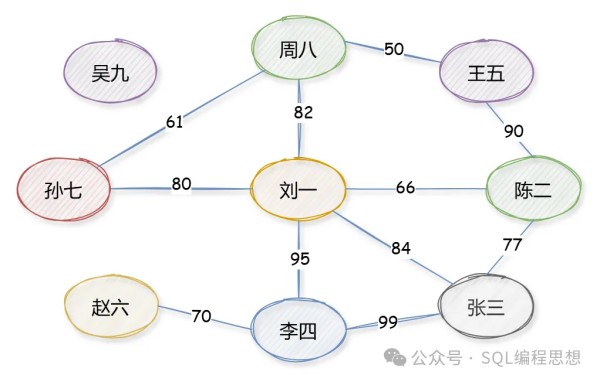
其中,“张三”和“李四”的关系最亲密,权重是 99。
加权图常见的应用还包括飞机航线图;机场是顶点,航线是边,边的权重可以是飞行时间或者机票价格。另一个例子是地铁换乘路线图,每个站点是顶点,地铁轨道是边,时间是权重。
粉丝关系图对于微博这种粉丝关注关系而言,需要使用有向图(Directed Graph)表示。因为关注是单向关联,A 关注了 B,但是 B 不一定关注 A。这种有向图的示意图如下:
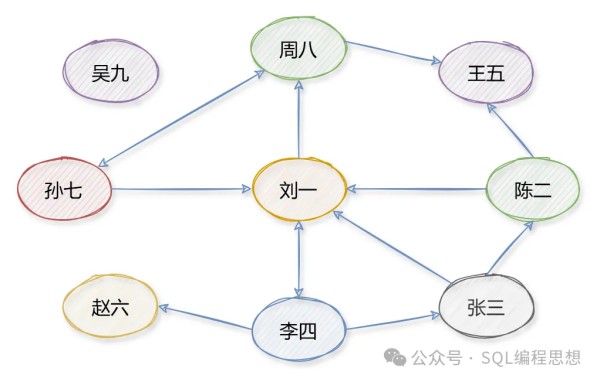
如果 A 关注了 B,图中就会存在一条从 A 到 B 的带箭头的边。上图中,“刘一”关注了“周八”,“刘一”和“李四”相互关注。对于有向图而言,度又分为入度(In-degree)和出度(Out-degree)。入度表示有多少条边指向该顶点,出度表示有多少条边是以该顶点为起点。“刘一”的入度为 4(微博中表示粉丝数),出度为 2(微博中表示关注的人数)。
数据存储对于图的存储而言,我们只要把顶点和边储存起来,那么图的所有信息就保存完整了。所以,一般有两种存储结构:邻接矩阵(Adjacency Matrix)和邻接列表(Adjacency List)。
邻接矩阵就是一个二维数组。对于上面的好友关系可以使用下面的矩阵表示:
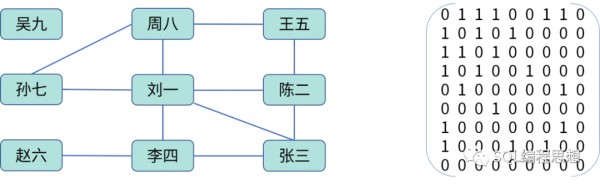
对于无向图,如果顶点 i 与顶点 j 之间有边那么 A[i][j] 和 A[j][i] 都为 1;上面的 A[1][2] 表示“刘一”和“陈二”是好友。
对于有向图,如果存在从顶点 i 指向顶点 j 的边,那么 A[i][j] 就为 1;如果也存在从顶点 j 指向顶点 i 的边,那么 A[j][i] 也为 1。对于加权图,数组中存储的数字代表了应的权重。
邻接矩阵虽然方便计算,获取两个顶点之间的关系时非常高效,但是存储空间利用率太低。首先,无向图中 A[i][j] 和 A[j][i] 表示相同的意义,只需要存储其中一个;因此浪费了一半的空间。其次,大多数的社交关系都属于稀疏矩阵(Sparse Matrix),顶点很多但是边很少。例如,微信用户数量已经超过 10 亿,但是大多数人的好友在几百人;意味着邻接矩阵中绝大多数都是零,浪费了大量的存储空间。
实际上我们能够在社交网络稳定交往的人数是大概是 150,参考邓巴数字。同时,许多社交软件也设置了好友人数上限,目前普通 QQ 用户通过 QQ 客户端添加好友的最高上限1500人。
我们再来看看邻接列表。上面的粉丝关注可以使用下面的列表描述:
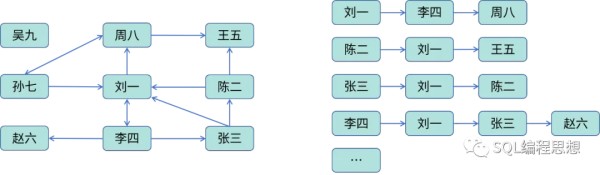
其中,每个顶点都有一个记录着与它相关的顶点列表。“刘一”关注了“李四”和“周八”,所以上面是一个关注列表。我们也可以创建一个逆向的邻接列表,存储了用户的粉丝。
对于好友关系这种无向图,可以认为每条边都是双向的,同样可以使用邻接列表存储。
邻接列表的存储更加高效,大部分操作也更快,例如增加顶点(用户)、增加边(增加好友、关注某人);但是查找两个顶点是否相邻时,可能需要遍历整个列表,效率相对低一些。
具体到数据库,我们可以为顶点创建一个表,为顶点之间的边创建一个表,从而实现邻接表模型。以下内容在 MySQL、Oracle、SQL Server、PostgreSQL 以及 SQLite 数据库中进行了验证。
好友关系分析
我们首先创建一个用户表和好友关系表:
create table t_user(user_id int primary key, user_name varchar(50) not null); insert into t_user values(1, '刘一'); insert into t_user values(2, '陈二'); insert into t_user values(3, '张三'); insert into t_user values(4, '李四'); insert into t_user values(5, '王五'); insert into t_user values(6, '赵六'); insert into t_user values(7, '孙七'); insert into t_user values(8, '周八'); insert into t_user values(9, '吴九'); create table t_friend( user_id int not null, friend_id int not null, created_time timestamp not null, primary key (user_id, friend_id) ); insert into t_friend values(1, 2, current_timestamp); insert into t_friend values(2, 1, current_timestamp); insert into t_friend values(1, 3, current_timestamp); insert into t_friend values(3, 1, current_timestamp); insert into t_friend values(1, 4, current_timestamp); insert into t_friend values(4, 1, current_timestamp); insert into t_friend values(1, 7, current_timestamp); insert into t_friend values(7, 1, current_timestamp); insert into t_friend values(1, 8, current_timestamp); insert into t_friend values(8, 1, current_timestamp); insert into t_friend values(2, 3, current_timestamp); insert into t_friend values(3, 2, current_timestamp); insert into t_friend values(2, 5, current_timestamp); insert into t_friend values(5, 2, current_timestamp); insert into t_friend values(3, 4, current_timestamp); insert into t_friend values(4, 3, current_timestamp); insert into t_friend values(4, 6, current_timestamp); insert into t_friend values(6, 4, current_timestamp); insert into t_friend values(5, 8, current_timestamp); insert into t_friend values(8, 5, current_timestamp); insert into t_friend values(7, 8, current_timestamp); insert into t_friend values(8, 7, current_timestamp);
其中,t_user 表用于存储用户信息;t_friend 表存储好友关系,每个好友关系存储两条记录。
如果是单向图结构(组织结构树),可以使用一个表进行存储。通常是为 id 增加一个父级节点 parent_id。
查看好友列表微信中的通讯录,显示的就是我们的好友。同样,我们可以查看“王五”(user_id = 5)的好友:
select u.user_id as friend_id,u.user_name as friend_name from t_user u join t_friend f on (u.user_id = f.friend_id and f.user_id = 5); friend_id|friend_name| ---------|-----------| 2|陈二 | 8|周八 |
“王五”有两个好友,分别是“陈二”和“周八”。
查看共同好友利用好友关系表,我们还可以获取更多关联信息。例如,以下语句可以查看“张三”和“李四”的共同好友:
with f1(friend_id) as ( select f.friend_id from t_user u join t_friend f on (u.user_id = f.friend_id and f.user_id = 3)), f2(friend_id) as ( select f.friend_id from t_user u join t_friend f on (u.user_id = f.friend_id and f.user_id = 4)) select u.user_id as friend_id,u.user_name as friend_name from t_user u join f1 on (u.user_id = f1.friend_id) join f2 on (u.user_id = f2.friend_id); friend_id|friend_name| ---------|-----------| 1|刘一 |
上面的语句中我们使用了通用表表达式(Common Table Expression)定义了两个临时查询结果集 f1 和 f2,分别表示“张三”的好友和“李四”的好友;然后通过连接查询返回他们的共同好友。关于通用表表达式以及各种数据库中的语法可以参考这篇文章。
可能认识的人很多社交软件都可以实现推荐(你可能认识的)好友功能。一方面可能是读取了你的手机通讯录,找到已经在系统中注册但不属于你的好友的用户;另一方面就是找出和你不是好友,但是有共同好友的用户。
以下语句用于找出可以推荐给“陈二”的用户:
with friend(id) as ( select f.friend_id from t_user u join t_friend f on (u.user_id = f.friend_id and f.user_id = 2)), fof(id) as ( select f.friend_id from t_user u join t_friend f on (u.user_id = f.friend_id) join friend on (f.user_id = friend.id and f.friend_id != 2)) select u.user_id, u.user_name, count(*) from t_user u join fof on (u.user_id = fof.id) where fof.id not in (select id from friend) group by u.user_id, u.user_name; user_id|user_name|count(*)| -------|---------|--------| 4|李四 | 2| 7|孙七 | 1| 8|周八 | 2|
我们同样使用了通用表表达式,friend 代表了“陈二”的好友,fof 代表了“陈二”好友的好友(排除了“陈二”自己);最后排除 fof 中已经是“陈二”好友的用户,并且统计了他们和“陈二”的共同好友数量。
根据查询结果,我们可以向“陈二”推荐 3 个可能认识的人;并且告诉他和“李四”有 2 位共同好友等。
最遥远的距离在社会学中存在一个六度关系理论(Six Degrees of Separation),指地球上所有的人都可以通过六层以内的关系链和任何其他人联系起来。在社交网络中,也有一些相关的实验。例如 2011年,Facebook 以一个月内访问 的 7.21 亿活跃用户为研究对象,计算出其中任何两个独立的用户之间平均所间隔的人数为4.74。
我们以“赵六”和“孙七“为例,查找任意两个人之间的关系链:
with recursive t(id, fid, hops, path) as ( select user_id, friend_id, 0, CAST(CONCAT(user_id , ',', friend_id) AS CHAR(1000)) from t_friend where user_id = 6 union all select t.id, f.friend_id, hops+1, CONCAT(t.path, ',', f.friend_id) from t join t_friend f on (t.fid = f.user_id) and (FIND_IN_SET(f.friend_id, t.path) = 0) and hops < 5 ) select * from t where t.fid = 7 order by hops; id|fid|hops|path | --|---|----|-------------| 6| 7| 2|6,4,1,7 | 6| 7| 3|6,4,3,1,7 | 6| 7| 3|6,4,1,8,7 | 6| 7| 4|6,4,3,1,8,7 | 6| 7| 4|6,4,3,2,1,7 | 6| 7| 5|6,4,1,2,5,8,7| 6| 7| 5|6,4,3,2,1,8,7| 6| 7| 5|6,4,3,2,5,8,7|
查询结果显示,“赵六”和“孙七“之间最近的距离是通过两个人(”李四“和”刘一“)进行联系。我们也可以统计示例表中任何两个用户之间的平均间隔人数:
with recursive t(id, fid, hops, path) as ( select user_id, friend_id, 0, CAST(CONCAT(user_id , ',', friend_id) AS CHAR(1000)) from t_friend where user_id = 6 union all select t.id, f.friend_id, hops+1, CONCAT(t.path, ',', f.friend_id) from t join t_friend f on (t.fid = f.user_id) and (FIND_IN_SET(f.friend_id, t.path) = 0) and hops < 5 ) select avg(hops) from t order by hops; avg(hops)| ---------| 3.5116|
对于 QQ 这种加权图,可以在 t_friend 表中增加一个权重字段,从而分析好友的亲密度。
粉丝关系分析
对于微博这种有向图,对应的表结构可以设计如下:
-- 粉丝 create table t_follower( user_id int not null, follower_id int not null, created_time timestamp not null, primary key (user_id, follower_id) ); insert into t_follower values(1, 2, current_timestamp); insert into t_follower values(1, 3, current_timestamp); insert into t_follower values(1, 4, current_timestamp); insert into t_follower values(1, 7, current_timestamp); insert into t_follower values(2, 3, current_timestamp); insert into t_follower values(3, 4, current_timestamp); insert into t_follower values(4, 1, current_timestamp); insert into t_follower values(5, 2, current_timestamp); insert into t_follower values(5, 8, current_timestamp); insert into t_follower values(6, 4, current_timestamp); insert into t_follower values(7, 8, current_timestamp); insert into t_follower values(8, 1, current_timestamp); insert into t_follower values(8, 7, current_timestamp); -- 关注 create table t_followed( user_id int not null, followed_id int not null, created_time timestamp not null, primary key (user_id, followed_id) ); insert into t_followed values(1, 4, current_timestamp); insert into t_followed values(1, 8, current_timestamp); insert into t_followed values(2, 1, current_timestamp); insert into t_followed values(2, 5, current_timestamp); insert into t_followed values(3, 1, current_timestamp); insert into t_followed values(3, 2, current_timestamp); insert into t_followed values(4, 1, current_timestamp); insert into t_followed values(4, 3, current_timestamp); insert into t_followed values(4, 6, current_timestamp); insert into t_followed values(7, 1, current_timestamp); insert into t_followed values(7, 8, current_timestamp); insert into t_followed values(8, 5, current_timestamp); insert into t_followed values(8, 7, current_timestamp);
其中,t_follower 存储粉丝,t_followed 存储关注的人。每次有用户关注其他人,往这两个表中插入相应的记录。
由于粉丝相对于好友是一种弱关系,能够分析的内容相对简单一些。
我的关注我们看看“刘一”关注了哪些用户:
select f.followed_id, u.user_name from t_followed f join t_user u on (u.user_id = f.followed_id) where f.user_id = 1; followed_id|user_name| -----------|---------| 4|李四 | 8|周八 |
“刘一”关注了“李四”和“周八”。
共同关注我们还可以进一步获取和“刘一”具有相同关注的人的用户:
select r.follower_id, r.user_id from t_followed d join t_follower r on (r.user_id = d.followed_id and r.follower_id != d.user_id) where d.user_id = 1; follower_id|user_id| -----------|-------| 7| 8|
结果显示,“刘一”和“孙七”共同关注了“周八”。
我的粉丝我们再来看看哪些用户是“刘一”的粉丝:
select f.follower_id, u.user_name from t_follower f join t_user u on (u.user_id = f.follower_id) where f.user_id = 1; follower_id|user_name| -----------|---------| 2|陈二 | 3|张三 | 4|李四 | 7|孙七 |
“刘一”有 4 个粉丝。
相互关注最后,我们看看哪些用户之间互为粉丝,或者互相关注:
select r.user_id, r.follower_id from t_follower r join t_followed d on (r.user_id = d.user_id and r.follower_id = d.followed_id and r.user_id < r.follower_id); user_id|follower_id| -------|-----------| 1| 4| 7| 8|
结果显示,“刘一”和“李四”互为粉丝,而“孙七”和“周八”则互相关注。
总结
本文介绍了如何将微信、微博这类图结构的社交网络数据使用邻接列表进行描述,并且最终存储为结构化的关系表。利用 SQL 语句中的连接查询、通用表表达式的递归查询等功能对其进行分析,发行其中隐藏的社交关系。
除了社交网络关系分析之外,这些 SQL 功能也可以用于飞机航班查找、地铁换乘路线查询,甚至用于实现各种推荐系统,例如产品的猜你喜欢与电影推荐。




